Via my father, a good example of a network-edge service that supplants an incumbent “smart network” service; Skype’s own voice mail offering.
(
link) [
del.icio.us/distobj]
Some comments on an interesting paper, but unfortunately yet another one that misunderstands REST.
(
link) [
del.icio.us/distobj]
Holy crap. Can we expect Google’s non-evilness to spread to the ICANN board now?
(
link) [
del.icio.us/distobj]
Robert Sayre goes Atom-only. Dude, that’s silly.
(
link) [
del.icio.us/distobj]
Now *that’s* cool. Unfortunately, worst … name … evar!
(
link) [
del.icio.us/distobj]
Jon transcribed a cool part of the Jim Gray Channel9 interview that stuck with me, in particular the bit about async complexity which seems bang on, I think. Certainly jives with my experience.
(
link) [
del.icio.us/distobj]
A quiz for Web services architects on SOAP message paths …
Say we had a purely SOAP based (i.e. not HTTP or other underlying
protocol issues to concern us) publish/subscribe configuration, with
three nodes; node A publishes to a queue at node B, and node C subscribes
to the queue at node B, receiving all documents published to B.
Now assume a scenario where C is already subscribed to B, and A publishes
a document to B;
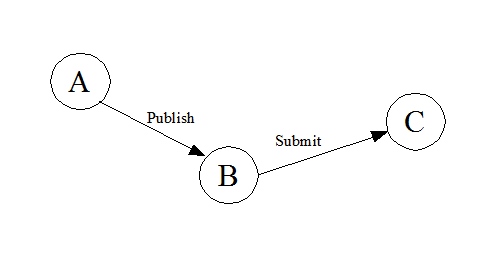
My question is, how many SOAP message paths did I just describe?
Scroll down for the answer.
I think there are two possible answers that people will give (though
only one correct one, of course 8-). One answer is that this is
one message path; A as sender, C as ultimate destination, and
B as a (non-terminating) intermediary. The other possible answer is that
there are two message paths; the first path with A as sender and
B as ultimate destination, and the second with B as sender and C as
ultimate destination (which also happens to make B a terminating
intermediary).
I think “two” is the correct answer, primarily because pub/sub is
about identity decoupling; removing the need for A to know about C.
Therefore C cannot possibly be the ultimate destination since A
doesn’t know it exists. From A’s POV, it’s sending the SOAP message
to B, period. And from C’s POV, it is receiving a SOAP message from
B, period. The SOAP envelopes sent along each path might be bitwise
identical, but they are different SOAP messages. FWIW, this
is why the SOAP spec
says
(as a result of a clarification request of mine, IIRC);
An ultimate SOAP receiver cannot also be a SOAP intermediary for the same SOAP message
Also note that any attempt on A’s part to try to identify a recipient
past B is known as
source routing,
and is, as a wise friend reminded me yesterday, the root of all evil.
As I
mentioned
on my other blog, I’ll be visiting the Bay Area again next week.
If you’d like to get together,
drop me a line.
That’ll make things a bit simpler for microformat developers
(
link) [
del.icio.us/distobj]
For those that might still care about the issue of WS-Addressing’s (and
possibly
SOAP 1.2’s)
abuse of the HTTP Request-URI,
some more information…
The semantics of Request-URI are unambiguous in RFC 2616;
The Request-URI […] identifies the resource upon which to apply the request.
Period. Over and out. Elvis has left the building. There are
dozens of commercial and open source implementations, and thousands of
deployed instances of those implementations, that count on that being
the case.
Now, if you buy the position of the WS-Addressing WG (and possibly even
of the XML Protocol WG in the form of SOAP 1.2), they’d have you believe
that the Request-URI identifies the next hop in the chain. Note that
this definition is different than the previous one.
Note to my friends; if you ever find me advocating a position that
attempts to redefine, in a non-backwards compatible way, a key part of
the most successful application protocol ever developed, you have my
permission to shoot me. Thanks.