“Tech Curmudgeon”, while probably still an accurate description of
my attitude towards so much “new” technology, wasn’t really conveying,
at a glance, what my weblog was (currently) about. So I’ve renamed it
“Web Things”.
There’s a double-entendre there, but you probably have to
be a Web-head to get it (or at least come down on the right side of the
httpRange-14 8-).
Though he didn’t use the words “self-description”, a good
article
nonetheless.
FWIW though, I think XML only provides the syntax in which
contextual information can be serialized. It’s a start, but we
need more.
A great quote
relayed by Jim Hendler, as told
by an old advisor of his;
“the only thing better than a strong advocate is a weak critic”
Heh. Too true.
Nelson writes;
Each of the individual applications using RDF I know of could have been done more easily with plain XML
Absolutely and unapologetically true.
But the statement misses the critical
lesson of software architecture (and architecture in general); only by
applying constraints can one realize useful properties. RDF/XML based apps
have more useful properties than does an XML based app; specifically,
“data silos”
are avoided.
Tim Bray just chimed in
on the whole Shirky issue, and is pretty much bang-on again. I’m not going to talk about that issue
though, but I wanted to discuss something Tim brought up, XBRL. He wrote;
Of course, if companies as a matter of routine posted XBRL versions of their financials at addresses like data.ibm.com and data.renault.com and data.hsbc.com and data.daimler-chrysler.com, a huge amount of time and money would be saved. And you’d have taken some useful steps towards a machine-processable web.
I think he’s right there, mostly. In the case of a bunch of XBRL/HTTP agents
(or indeed any data format and HTTP), you have a machine processable system,
and a pretty darned useful one too; I’m not trying to diminish the value that would
provide at all by these comments. But it’s just a system, one
that doesn’t have anything to do with (i.e. has no way to integrate with) any other
HTTP based system. It’s a silo.
Where we really want to get to, is to do away with silos entirely. The Web solved the
“protocol/interface silo” problem (though many still don’t recognize that). Now, phase two will
aim to solve the “data silo” problem (which the example above is a case of). I don’t know if it
will work or not, but we’ve got the right team on the job IMO.
BTW, I also liked Tim’s comments about betting against TimBL, and “shooting fish in a barrel”.
It reminds me of an earlier
blog entry
I made about Jeremy Allaire, and indirectly Adam Bosworth, saying that TimBL was “on another
planet”. Heh, right.
Dave has written a
great piece on loose coupling for Webservices.org. It really breaks things down well,
including a list of 10 ways in which loose coupling can be achieved. That list, *GASP*,
even includes “constrained interfaces”.
As you might expect, I disagree with Dave on some stuff. But most of it is pretty
accurate, I’d say. Where I disagree with him,
again,
is where he starts talking about the role of humans. In several places, he correctly points out
where, in the process of browser-based Web surfing, humans currently enter the equation.
But then, in most cases without any evidence that he’s thought about the issue at any
depth, automatically assumes that because humans currently do it, machines can’t,
concluding with the implicit assumption that the Web isn’t currently good for automata
and therefore needs Web services.
I really wish he would take the time to explore that hypothesis of his in more
detail, because it’s not like you have to look too far to see how automata have been
integrating with one another using constrained interfaces; there’s an entire
branch of distributed computing
devoted to it. Allow me to paste a relevant snippet from that link;
Large systems of distributed, heterogeneous software components play an increasingly important role within our society. The paradigm shift from objects to components in software engineering is necessitated by such societal demands, and is fuelled by Internet-driven software development. Using components means understanding how they individually interact with their environment, and specifying how they should engage in mutual, cooperative interactions in order for their composition to behave as a coordinated whole. Coordination models and languages address such key issues in Component Based Software Engineering as specification, interaction, and dynamic composition of components.
If I hadn’t mentioned that, and you stumbled upon it in an article like Dave’s, you’d
think that was talking about Web services, wouldn’t you? Surprise.
Don Box asks;
In a world in which all SOAP messages have <wsa:Action> header blocks, why
do my Body elements need XML namespace qualification?
First order answer; I’d say simply because an intermediary that doesn’t know the
value of the Action header might want to look at the payload.
Second order answer; I think it’s a fairly small & uninteresting world where it
would it make sense to have Action headers within the SOAP envelope. In order for
SOAP to make proper use of application protocols (well, transfer protocols at least),
SOAP headers should be constrained to containing representation data and metadata, as
that’s the data that remains constant between hops over different application protocols. For
example, through a HTTP to SMTP bridge, a SOAP envelope should remain constant. “Action”
is message metadata, and therefore does not necessarily remain constant between
different protocols; it’s hop-by-hop.
Where it would make sense to put the Action header (and other non-representation
headers) in the SOAP envelope, is when SOAP is used with transport protocols. But I don’t
think there’s much value to that, at least in the short/medium term; the value of reusing
established application protocols is too great.
Here I was, working on a rambling retort to Clay, when Sam nails it;
Two parts brilliance, one part strawman. Pity, actually, as I am sympathetic with the point that Clay is trying to make.
Rest assured, this “problem” isn’t unknown to Semantic Web folk. It’s actually an
official TAG issue,
goes by the moniker “public meaning”, and has its very own
task force
to tackle it (and unlike other task forces, they’re actually making progress!).
FWIW, my view (explained partially here)
is that although this is another one of those
unmaskable problems in distributed systems,
that doesn’t mean there’s not a way forward.
Consider the HTTP 404 response code. I see it as a boundary case of the public meaning
issue, where ambiguity is maximized due to having no available information from
which to infer meaning, leaving public meaning to be determined solely by use, just as with
Clay’s “People” example. But did the Web stop working because of 404? Of course not.
404 is a feature, not a bug, as Clay himself
observed.
The Web works “despite” 404, because there’s public value in not using it, just
as there’s public value in being as unambiguous about URI semantics as need be.
Will there be ambiguity on the Semantic Web? Of course. You still get 404s, right?
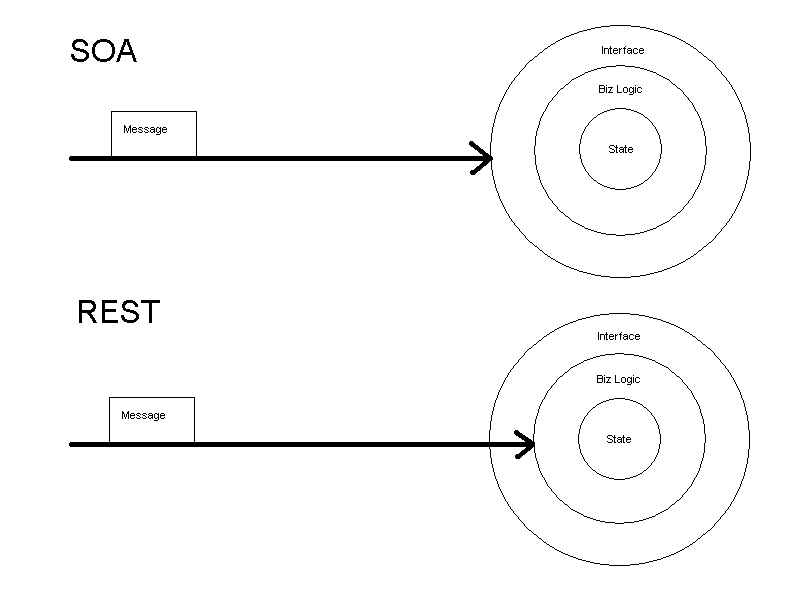
Don’t get hung up on the “object” there; it’s a logical view.
The picture is meant to capture the essence of what I see as the
fundamental misunderstanding/mistake of Web services. This
misunderstanding goes by several names;
- transport vs. transfer;
transfer gets you all the way to the business logic, while transport only gets you as far as the interface.
- tunneling
- uniform vs. specific interfaces
- late binding; an identifier is sufficient to get you direct access to the state & logic
- a priori information;
see late binding; deployed agreement on HTTP & URIs suffices
When I hear “application integration”, I’m thinking the bottom picture, not the top,
because APIs just get in the way.
Don Box
responds
to Jon Udell regarding XAML. He writes;
XAML is just an XML-based way to wire up CLR types – no more no less.
That’s not how XAML comes off at all. In the examples, there are
names such as “TextPanel” and “Heading” in the XAML namespace; those
aren’t the sort of things I’d expect in a binding language.
But if the examples are just misleading, and Don’s statement
is taken at face value, what XAML would actually be aiming to replace
isn’t HTML/CSS, it’s RDF/RDF-Schema;
<Object def:Class="MyClass" />
is essentially equivalent to;
<my:MyClass>
<rdfs:subClassOf rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Resource"/>
</my:MyClass>
Hmm.