The real issue with protocol independence, I believe, is the
word “protocol”; that the two camps in this debate – the Web/Internet
folks, and the Web services folks – each have their own, quite
different, definition of the word. For Web services proponents,
“protocol” means one thing and one thing only; a spec whose job it is
to move bits from point A to point B over a network.
Meanwhile, for the Web/Internet crowd, “protocol” has a much broader
definition. In common use, it encompasses the “bit moving” specs, but
also others which do a lot more than simply move bits (more below).
Some even (properly, IMO) refer to the data formats, such as HTML, as
protocols, though you don’t see that too often any more.
As if this disconnect wasn’t bad enough, another – interface
constraints – compounds the problem. Specifically, Internet based efforts
(including the Web, of course) always start with an interface constraint.
This is simply for the reason that they’re (usually) always focused on a
single task – for example,
email exchange,
mail folder access and synchronization,
file transfer –
and pay little to no attention to what it means to define interoperability
between those applications, since that’s tangential to their primary
objective. A consequence of this approach is that there becomes little
value in using a common sub-layer-7 protocol (like BEEP, IIOP, or how
most people use SOAP). This has enormous benefit, with the big one being
it permits the
mechanics of mapping onto the network
to be optimized for the semantics; consider that without GET, HTTP wouldn’t have
needed a bunch of features, in particular caching. When semantics are detached
from the “wire format” (as with BEEP et al, as mentioned previously), it’s
optimized for no particular application, thereby
resulting in poor performance
for practically all applications.
I’ve drawn a diagram that I hope helps explain these two different
views;
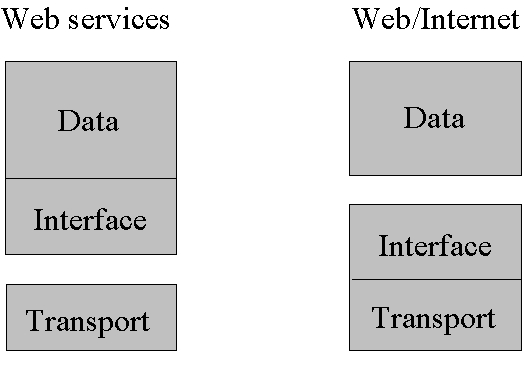
Hopefully you’ll at least see the fundamentally different visions
of the stack in play here, and perhaps better appreciate my concern about
“protocol independence”. Protocols play a much more important role in the
stack on the right than they do in the one on the left!